
Just passing along a quick note from the world of academia; I, along with my adviser from Brown, Dr. Roee Gutman, published our first paper together.
It’s titled ‘Estimating the average treatment effects of nutritional label use using subclassification with regression adjustment,‘ and presents a case study of how to measure the causal effects of an ordinal exposure. The article is currently online in Statistical Methods in Medical Research.
The online version (paywall) of the article is linked here. You can also download a pre-published version on the arXiv by going here. Finally, here’s the abstract and keywords.

What is the main point of this paper?
Here’s one of my favorite parts, a graph showing the covariates’ bias before and after subclassifying subjects into groups. In this and many other examples, subclassifying is an important tool as it allows for more of an apples-to-apples comparison. Specifically, it only makes sense to contrast the outcomes of subjects in observational data if they are similar on pre-treatment covariates, as traditional tools like regression adjustment require extrapolation and are prone to bias.
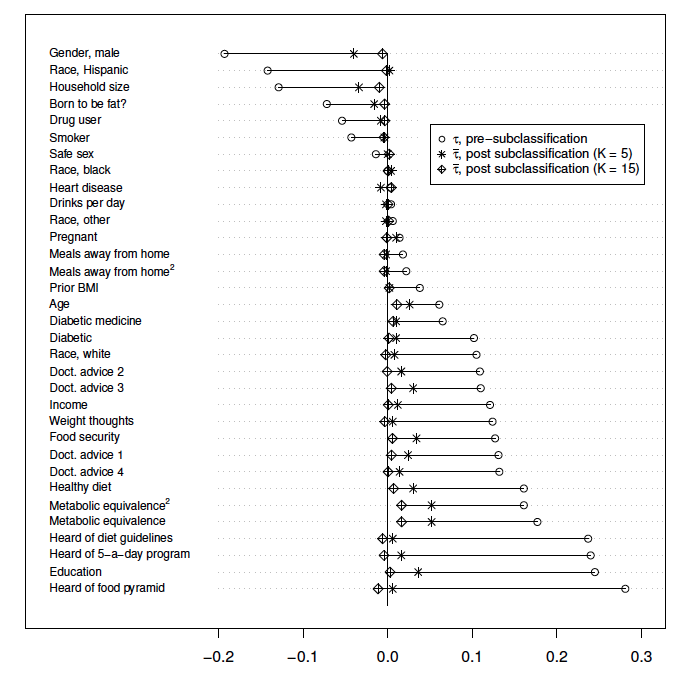
In the graph above, the vast majority of covariates were significantly associated with our ordinal exposure (nutritional label use) before the grouping of subjects into subclasses. After subclassifying (especially with 15 subclasses), most of that covariates’ bias had been removed, as shown by Kendall’s Tau values near 0.
If you are interested in the published version of the paper, feel free to drop me an email and I can send it over. And if you are still reading, I’m also glad you are interested in causal inference!

Reblogged this on Stats in the Wild.